
Distributed consensus and the Raft algorithm
03 Feb 2017 | distributed-systemsRaft is an algorithm for distributed consensus, created by Diego Ongaro and John Ousterhout from Stanford University. The main drive for the creation of Raft was the fact that Paxos, while widely considered the standard distributed consensus algorithm for over a decade, was also considered very hard to understand. The authors’ intention thus was to come up with a different, easy to understand distributed consensus algorithm. In this post I will try to give an introduction to the Raft algorithm.

Distributed consensus and Replicated state machines
In short, consensus means that multiple distributed nodes agrees on the a system state, presenting to the outside world the illusion of a single machine, even in the presence of failures. This is very valuable, because it allows us to take a relatively unreliable machine (prone to crashes and failures), deploy several copies of it and get a relatively reliable system, which can cope with failures of individual machines.
In more detail, we use a model called Replicated State Machines. By state machine we mean some sort of program which responds to outside stimulus (usually in the form of commands coming from clients over the network) and manages some sort of internal state. This is a pretty general model which fits most of what we usually think about as services today. Replicated state machines simply means that we increase the reliability of the system by taking one such state machine and running several replicas of it on several different machines. The goal is to have each of the replicated machine run the same set of commands in the same order, so all machines’ states are synced. Now the system is up as long as a majority of the machines are up and agree on the current state.
Basic Terminology
Node States
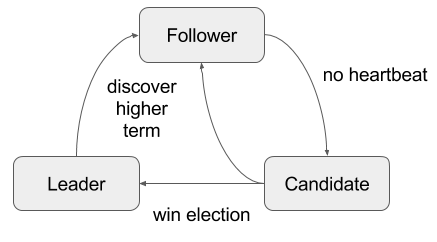
Every node in the cluster can be in one of 3 states: leader, candidate or follower.
- Leader: an active node which is currently leading the cluster. Handles requests from clients and replicates state to follower nodes.
- Candidate: an active node which is attempting to become a leader. Interacts with the other nodes by sending requests for votes.
- Follower: a passive node which only responds to RPCc and does not initiate any communication. All nodes start in the follower state
Terms
Time is divided to terms. Each term begins with a leader election, and a leader reigns throughout the term. In some cases no leader is elected (a split vote), so a new term will be started on the next leader election. Terms are represented by positive integers. Note that there is no such thing as the global term number. Instead, each node views the current term somewhat differently. Nodes include the term number when communicating with other nodes. If a node (even a leader) receives a message containing a term which is higher than his own, it immediately goes back to being a follower and updates his term number. Nodes persists his term number to disk, so it can be retrieved in case of crash or restart.
Commands log
As mentioned above, commands causes transitions in the node’s state machine. Commands are not applied immediately. Instead, each node maintains a commands log:
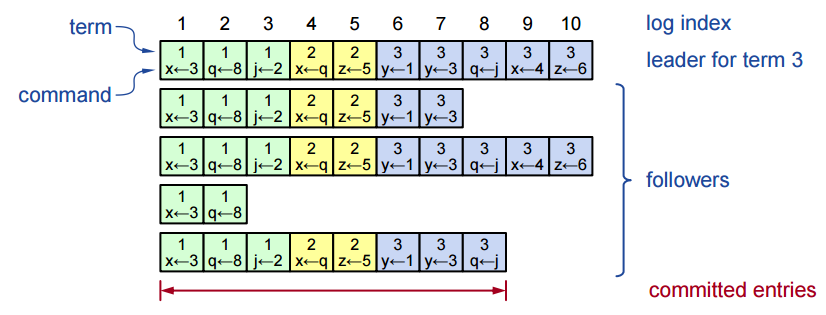 diagram credit
diagram credit
As can be seen, commands are arranged by index. Each command is held with its term number.
Before committing a command, it must be safe, which means it was replicated by the leader in a majority of the servers. The commands log must survive crashes so it is persisted on disk.
Leader Election
Each follower node holds an election timeout, which is the amount of time the follower will wait before becoming a candidate. The election timeout is initialized to some random value in a fixed interval
(e.g., 150ms-300ms). As long as the leader is alive, it keeps sending heartbeat messages (also known as APPEND ENTRIES message) to all nodes in the cluster. any node receiving
a heartbeat message will reset his election timeout back to some random value. If, however, the leader node dies, and a follower’s election timeout will reach zero, this node will
changes state to candidate and will starts a new leader election term. In it, the candidate:
- Increments its current term value
- Votes to himself
- Sends
REQUEST VOTEmessages to all other nodes in the cluster
Other nodes respond to the vote request by voting to the first request containing term number which is higher than their own. They also update their term number and goes back to follower state, as mentioned above. Once a node receives votes from a majority of the nodes, he announces himself as the new leader. If a candidate node receives this announcement, it immediately changes state to a follower. If, however, no node gets a majority of the votes (for example, when two candidate each gets half of the votes) then no leader is elected in this term. Eventually some other node’s election timer will timeout and a new leader election will start.
The requirement for a majority of votes ensures that only at most one leader will be selected in a term (safety), while the randomized initial timer values ensures that eventually some leader will be selected (liveness).
The leader election flow is summarized in the following chart:
Log replication
Once a leader has been elected, it begins servicing client requests. In normal operation, clients interact only with the leader, issuing commands to be executed in the state machine.
The leader appends the command to the end of his log and sends APPEND ENTRIES with the command to the followers.
The followers append the command to their logs as well, and sends ack back to the leader. Once a majority of the followers have approved the append, the command is considered safe and
the leader executes it in his state machine and returns the result to the client. The leader then notifies the followers (using subsequent APPEND ENTRIES messages) that they can
commit the message in their state machines as well.
If a follower has crashed or is slow to respond, the leader keep retrying in subsequent messages until the follower responds.
Maintain consistency between logs
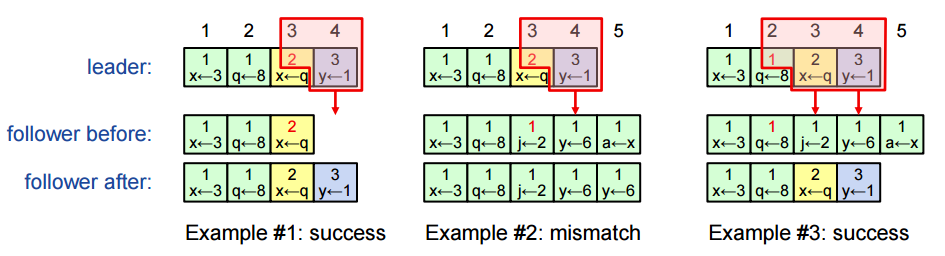
Raft is able to detect and fix inconsistencies in the commands logs between different nodes. To do so, we defined the log matching properties:
- If log entries on different servers have the same index and term, then:
- they store the same command
- the logs are identical in all preceding entries
- If a given entry is committed, all preceding entries are also committed
To maintain this property, the leader includes in the APPEND ENTRIES message the <index, term> of the entry preceding the new one(s). When a follower receives such message,
it first checks of the <index, term> exists in his log. If not, it rejects and the leader retries with lower log index.
References
- Raft website
- The secret Lives of Data - a nice Raft visualization
- The Raft paper (pdf)
Comments